Tesseract OCR
Open Source Optical Character Recognition
Tesseract OCR is an open-source tool to read text in pictures and convert it into editable digital text. Perfect for scanning textbooks, documents, or notes into searchable formats. Useful for developers, students, and professionals who need accurate text extraction.
What is Tesseract OCR?
Tesseract is an Optical Character Recognition OCR software tool that extracts printed and, with training, some handwritten texts from pictures and PDFs and converts them into editable, machine-readable text. The original developer was Hewlett-Packard (HP) and was open sourced in 2005 has been community-maintained within the tesseract-ocr organization (Google sponsored development from 2006 to November 2018).
It supports more than 100 languages and is completely free, which is why it is available to everyone. The current stable version is Tesseract 5.x; Tesseract 4 introduced a modern LSTM (neural network) OCR engine that improved accuracy. It supports 100+ languages (the exact set depends on the installed trained data files).
Tesseract software is compatible with different programming languages and frameworks with wrappers like pytesseract for Python. It can be used directly via the command line or with an API.
OCR Made Simple with Tesseract

Key Features
Powerful, flexible, open-source OCR capabilities
Open Source
Free to use for personal and commercial work under Apache License 2.0.
100+ Languages
Supports over 100 languages and 37 scripts using trained data models.
LSTM Neural Engine
Modern LSTM-based recognition for higher accuracy on printed and handwritten text.
Multiple Output Formats
Export to TXT, hOCR, TSV, PDF (searchable), or XML formats.
Command Line Support
Process images quickly using CLI commands or automation scripts.
API Integrations
Use in Python (pytesseract), C++, Node.js, Java, and other frameworks.
Trainable Models
Train custom OCR datasets for new languages, fonts, and formats.
Unicode Support
Accurate handling of international scripts, accented characters, and symbols.
Page Layout
Detects columns, borders, images, and paragraphs for better document structure.
Download Tesseract OCR
Grab the latest stable release and start extracting clean, searchable text from your images in seconds.
How to Download and Install Tesseract OCR
Download and set up Tesseract for Windows, macOS, Linux and Python.
How to Install Tesseract OCR?
For Windows:
- Download the .exe file of Tesseract OCR for Windows
- Run the downloaded file and select your installer language.
- Accept the terms and agreements.
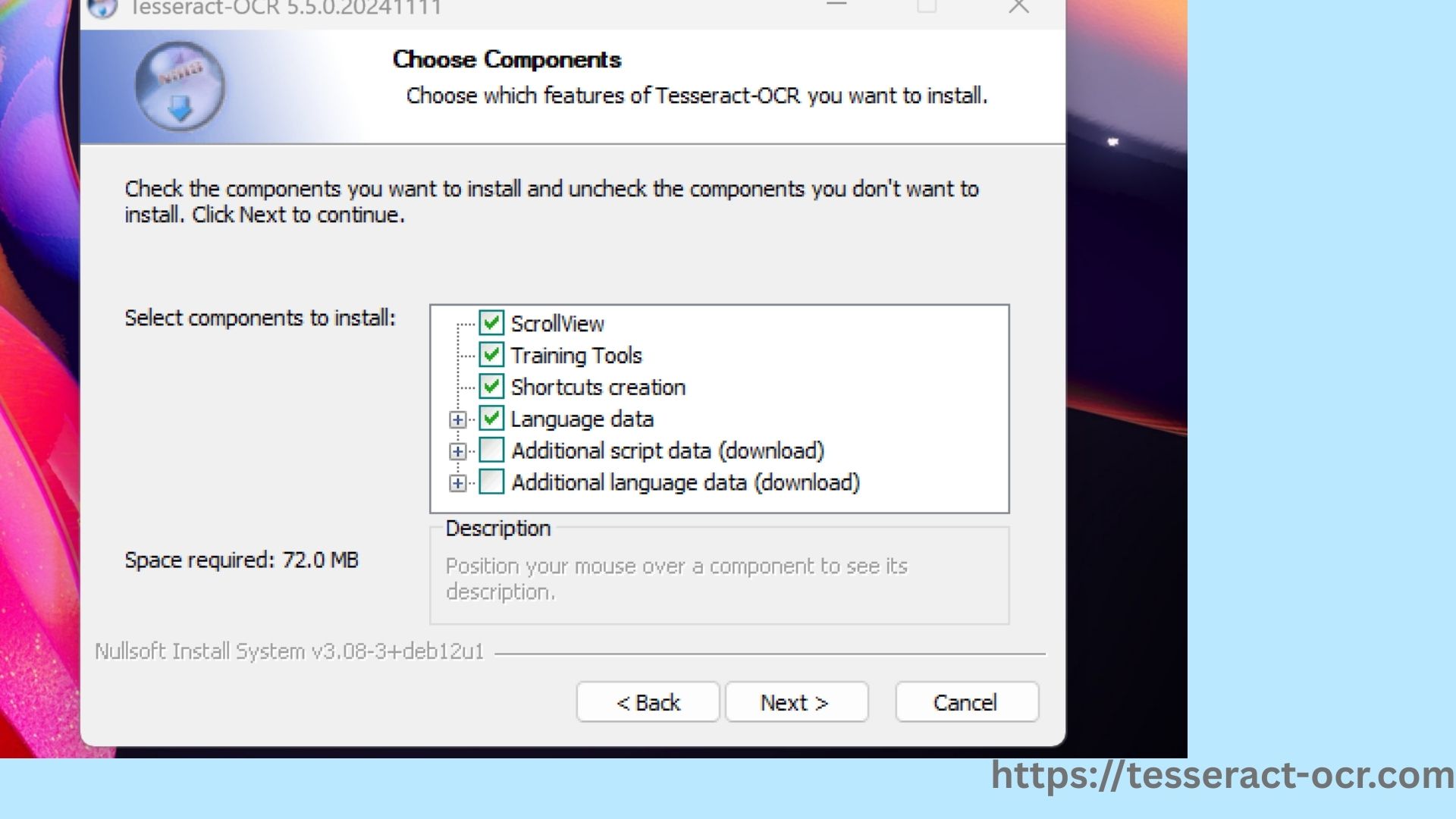
- In the components section, select your language (English).
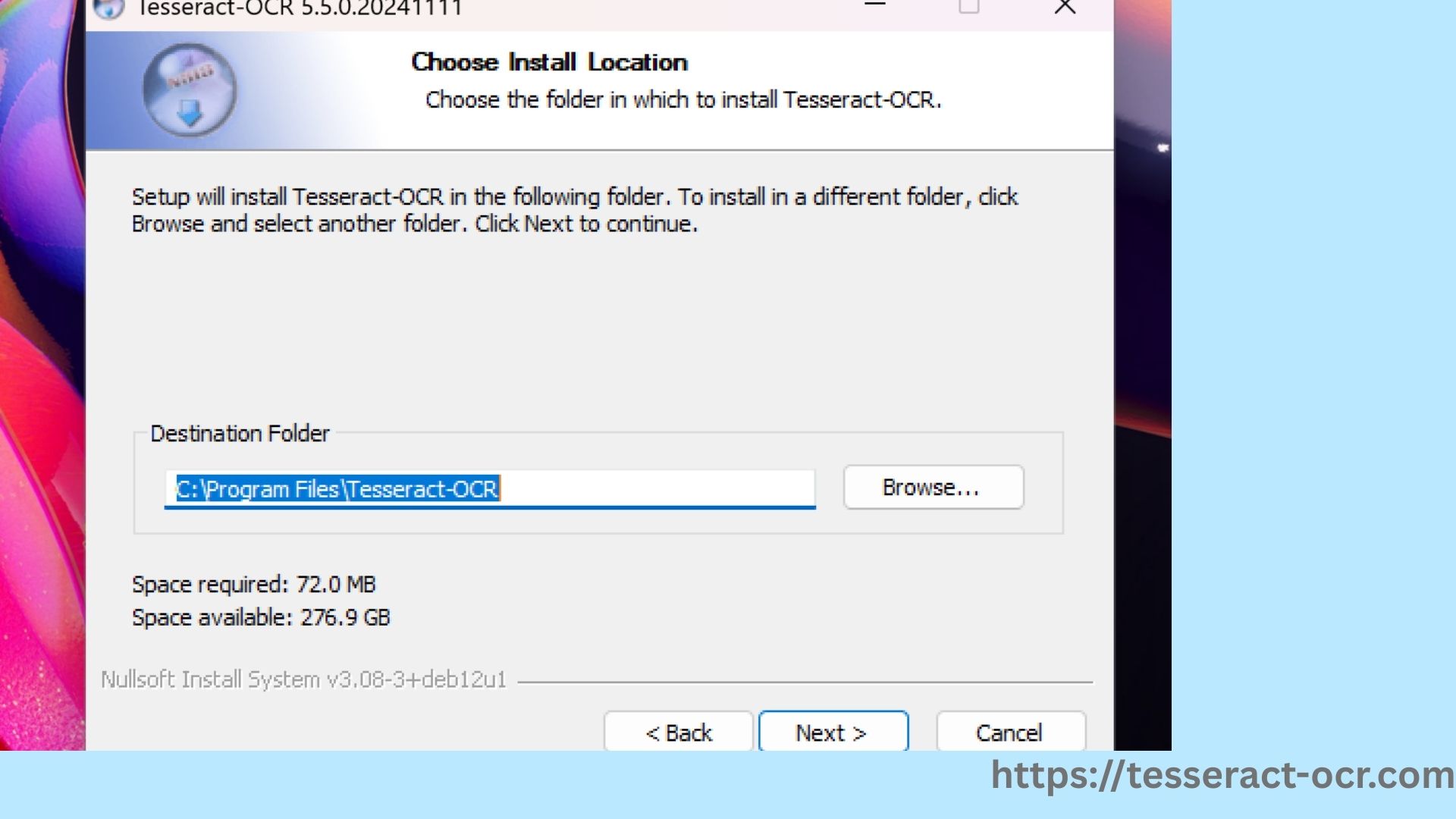
- Choose the installation directory (C:\Program Files\Tesseract-OCR) and copy it for configuration.




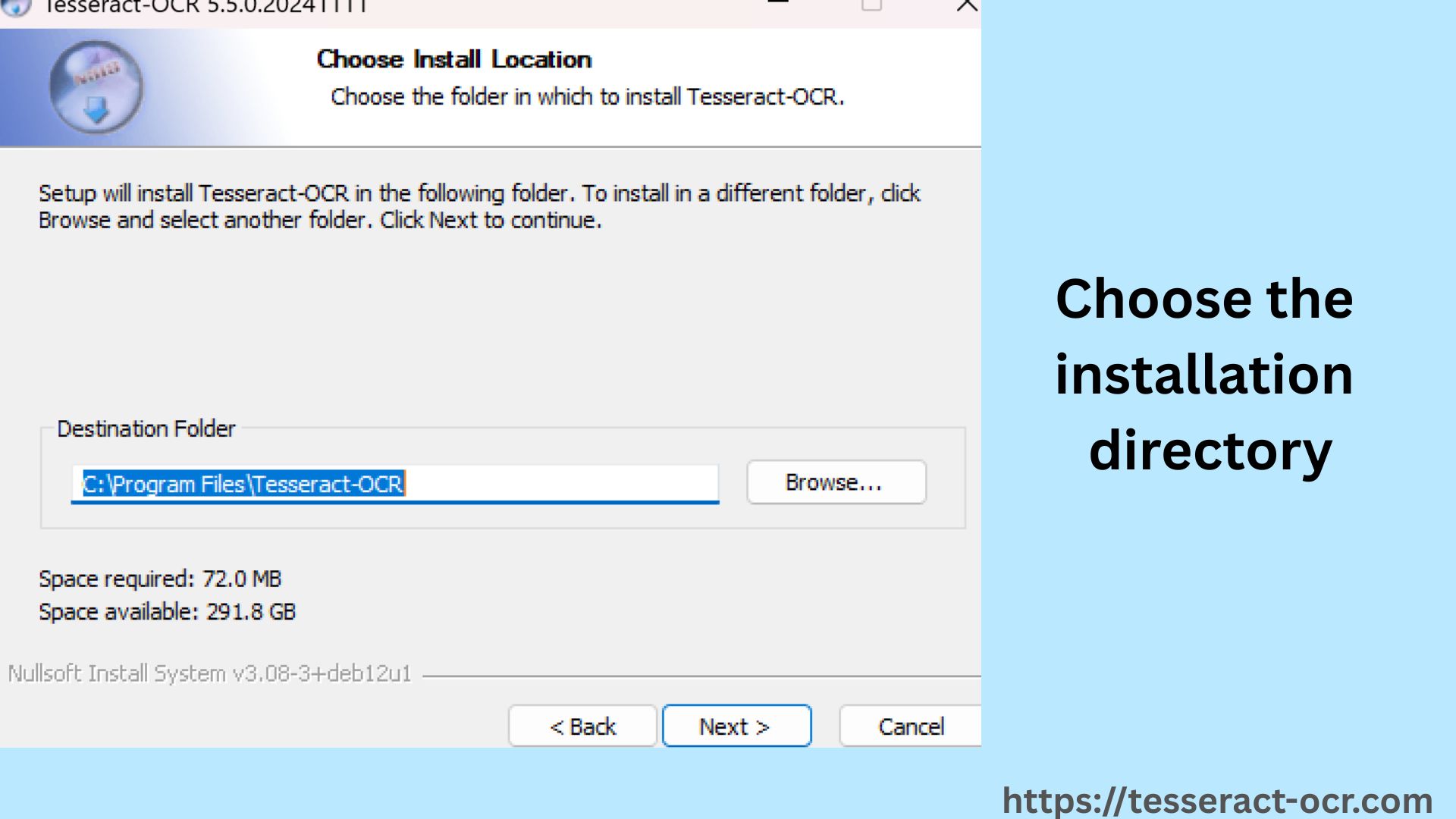
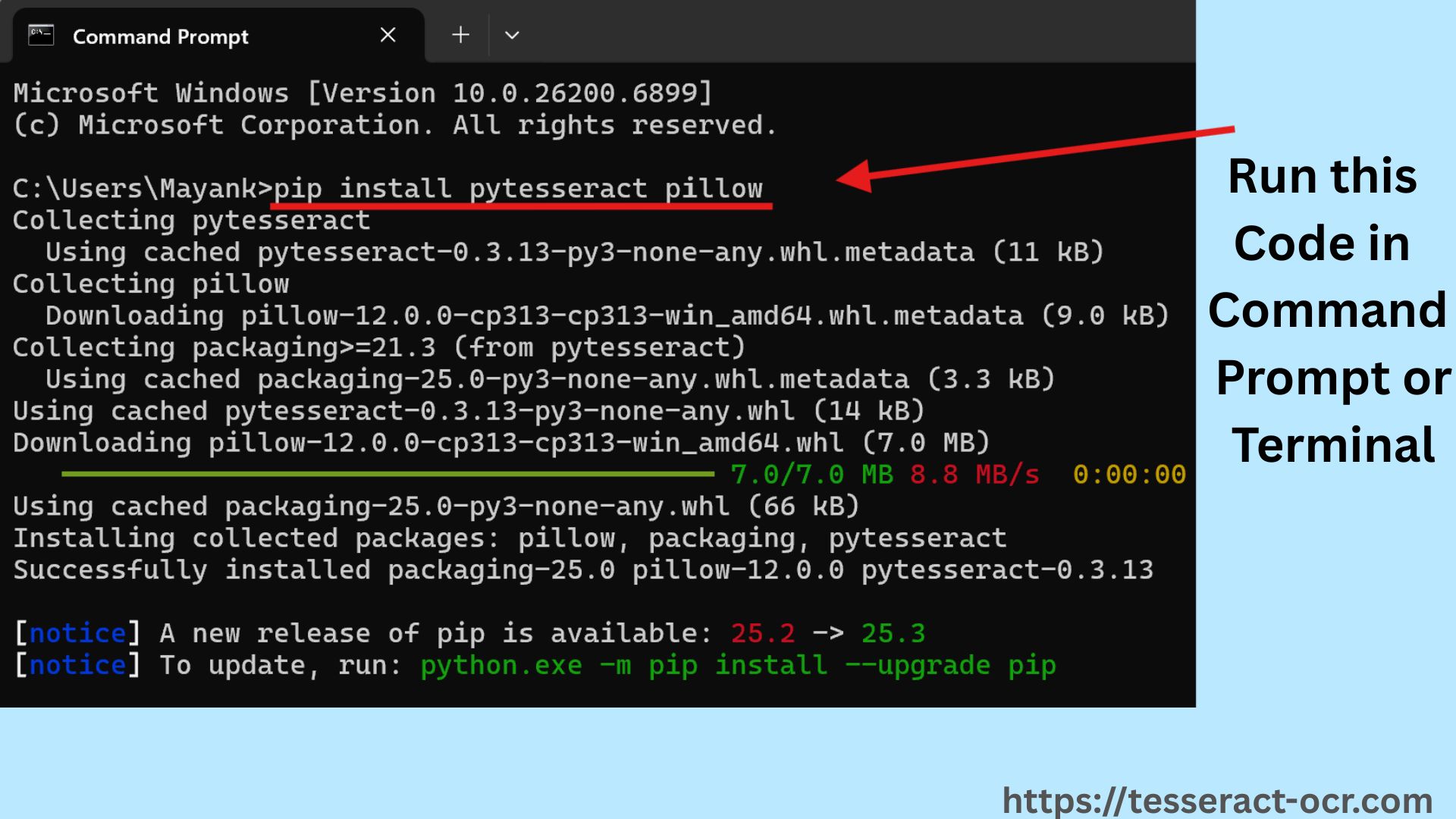

How To Launch Tesseract OCR?
Windows setup, Python usage, and Linux/macOS command-line examples.
- Go to the System Environment Variables Settings and search for Environment Variables in Windows search.
- Under the System Variables, look for the Path variable and Edit it.
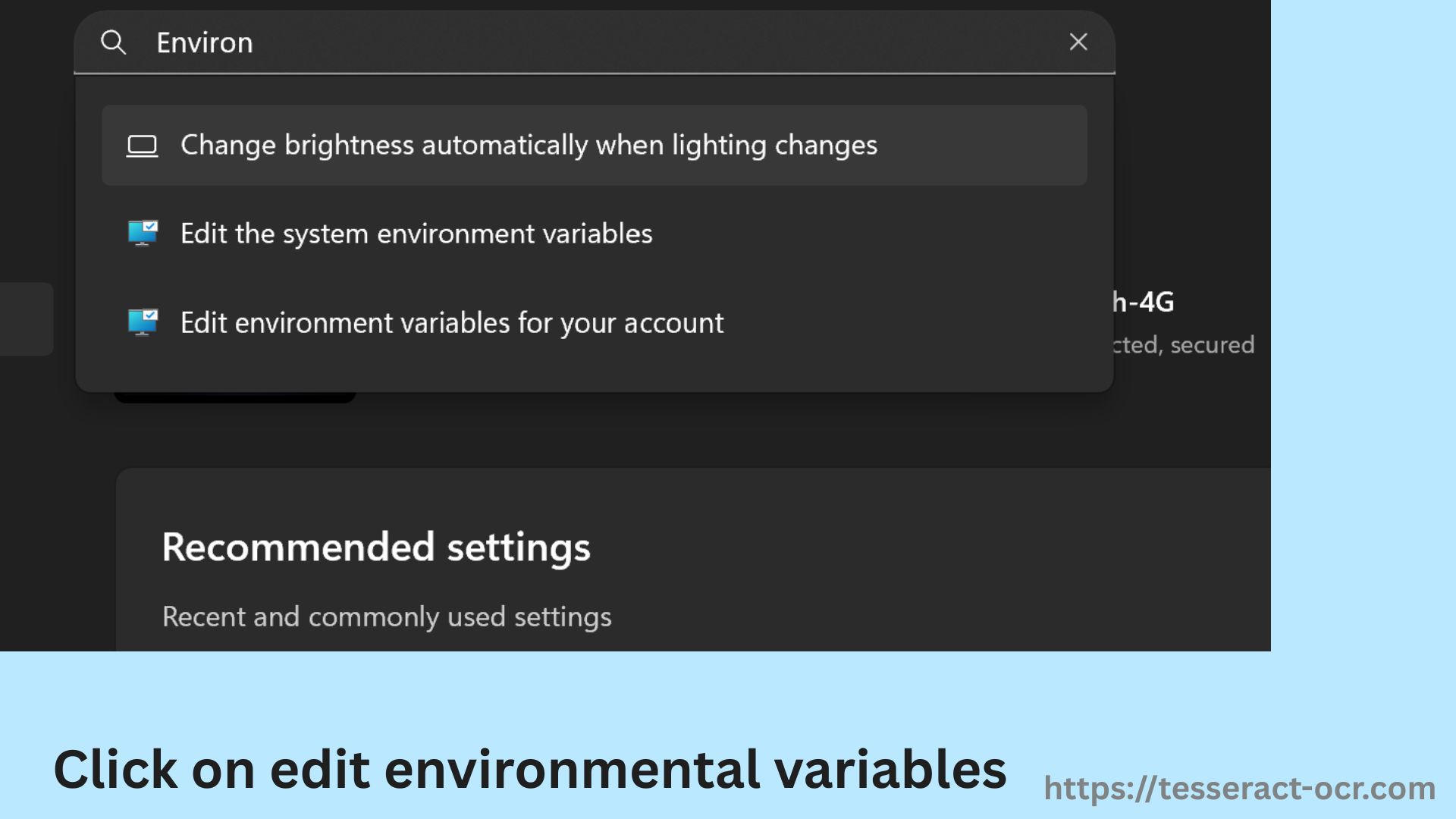
- Select New and paste C:\Program Files\Tesseract-OCR.
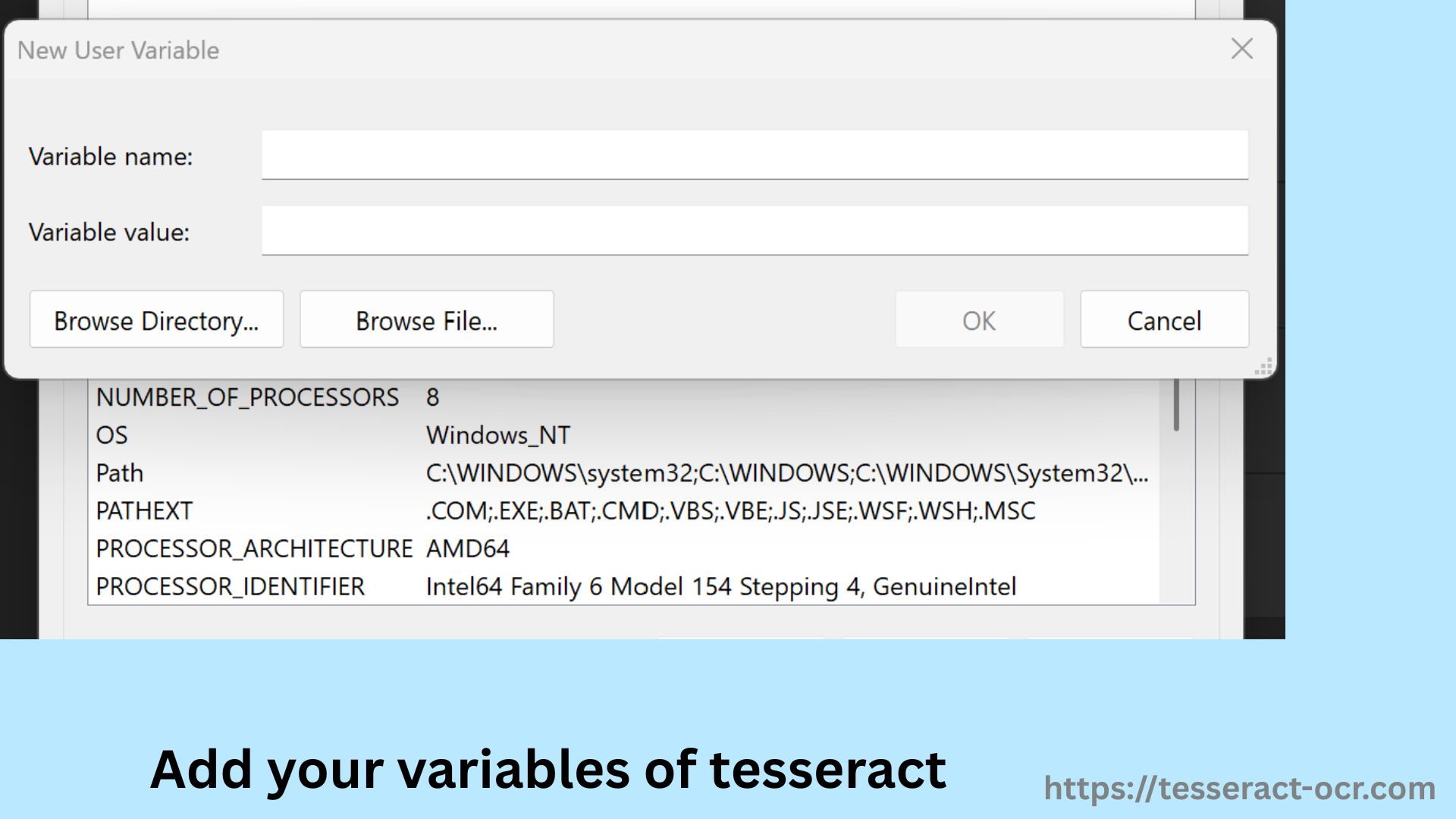
- Now, in the same Environment Variables under System Variables, click New.
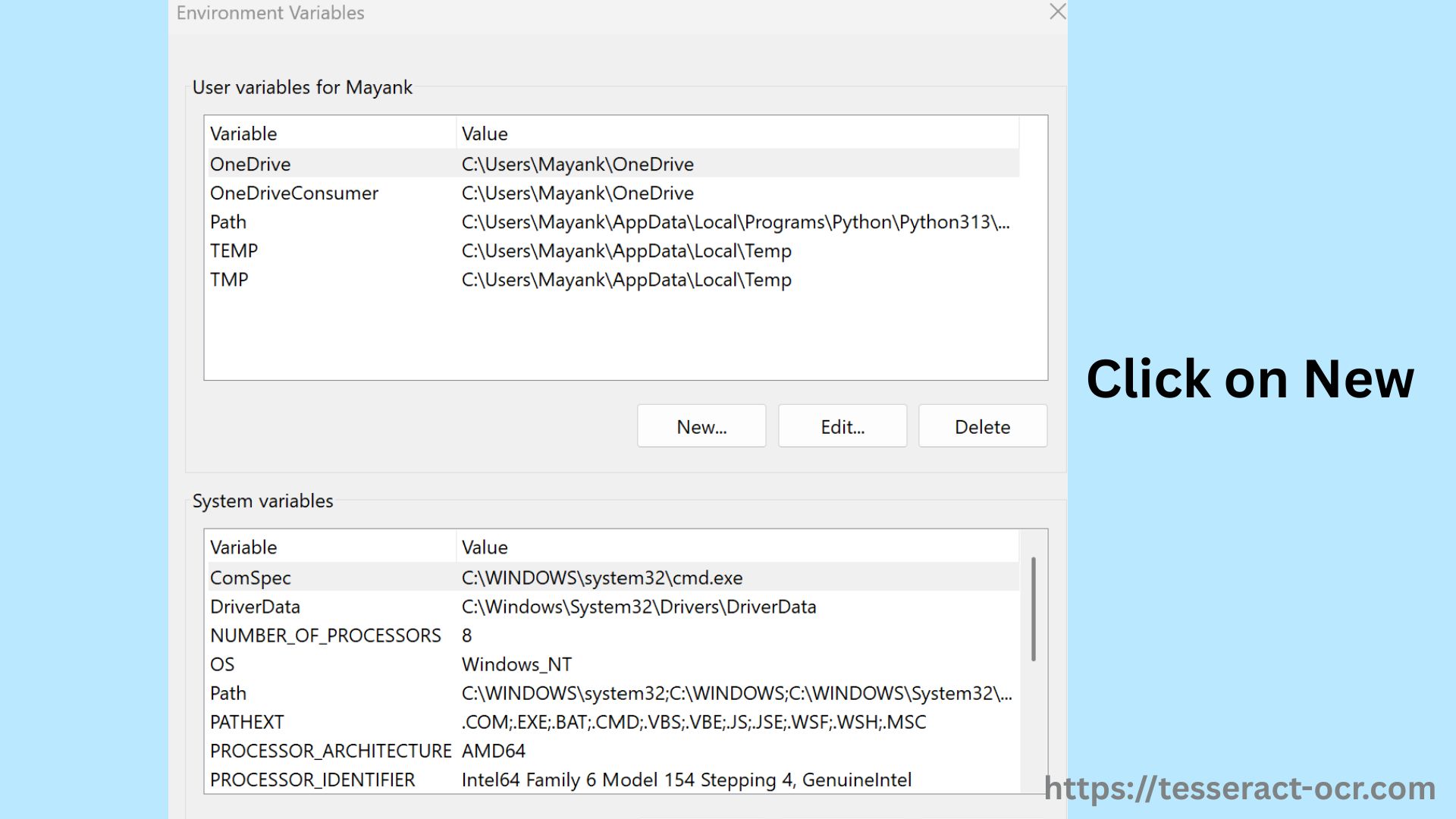
- Set Variable name: TESSDATA_PREFIX and variable value as: C:\Program Files\Tesseract-OCR\ (the parent directory of tessdata), or you can use the --tessdata-dir option when running Tesseract commands.
- Verify by opening a new Windows Command Prompt.
- Run the command: tesseract -v.
If the installation was successful, the command will show the details of Tesseract OCR.
Video Overview
Features in Detail
A deeper look at what makes Tesseract OCR powerful
Supports 100+ Languages
Tesseract has robust Unicode (UTF-8) support and can recognize over 100 languages. Modern LSTM models (introduced in v4) expanded language coverage and quality, with many traineddata packs available for different scripts.
Supports Input Formats
Accepts common image formats such as PNG, JPEG, TIFF and more — making it compatible with screenshots, scanned pages, and images generated by deep-learning pipelines.
Supports Output Formats
Exports results to TXT, hOCR (HTML), TSV, searchable PDF, PAGE XML, and ALTO XML (availability depends on version and traineddata).
Engine Modes
Tesseract provides multiple engines: the legacy (pattern) engine and the modern LSTM neural engine. Use the --oem flag to choose: 0 (legacy), 1 (LSTM), 2 (both), or 3 (default/auto).
Page Layout
Detects document structure — columns, borders, images and paragraphs — and distinguishes monospace/code from proportional text for better extraction fidelity.
Trainable
Train or fine-tune LSTM models for new languages, fonts or specialized datasets. Training yields best results with high-quality ground-truth data and careful preprocessing.
API / Wrapper Access
Use Tesseract via its native C/C++ API or through language wrappers such as pytesseract (Python), tess4j (Java), and node-tesseract (Node.js).
Dual Engines (Summary)
Legacy and LSTM engines coexist to provide flexibility across use-cases. Choose the engine mode that fits your input quality and performance needs. Visual and theme styles in this section match the rest of the site.
Why Should You Use OCR?
OCR makes working with text faster, smarter, and more efficient in daily life and business workflows.
Faster than Manual Typing
OCR converts printed or handwritten text into editable digital text instantly. No need to retype entire pages.
Searchable Documents
Once converted, documents become searchable, indexable and organized for quick information retrieval.
Perfect for Study & Notes
Scan textbooks, notes, worksheets, and convert them to editable text for better studying and referencing.
Office Productivity
Convert scanned business papers, invoices, bills, receipts, ID cards, and official forms into usable digital text.
Supports Multiple Languages
OCR tools like Tesseract support 100+ languages, including English, Hindi, Arabic, Chinese, and more.
Useful in Automation & AI Tasks
OCR is widely used in machine learning, document processing systems, RPA workflows, and data extraction bots.
How Tesseract OCR Works
From raw image to clean, searchable text in four clear steps
Preprocessing
Clean the image for best results: deskew, denoise, convert to grayscale/threshold, and boost contrast so text stands out.
Layout Analysis
Detect text regions and structure (blocks → paragraphs → lines → words) so multi-column pages read correctly.
LSTM Recognition
Run the neural LSTM engine to read full lines of text, using the selected language model(s) for higher accuracy.
Post-process & Output
Spell/heuristic fixes and export: plain TXT, TSV, hOCR, or searchable PDF ready to copy, edit, and search.
- The input image is cleaned up to maximize clarity, a process known as image preprocessing. Tesseract converts the image to greyscale, removes noise, and corrects rotation to align the text horizontally. After this, it performs Layout Analysis to identify and organize text into components such as blocks, paragraphs and singular lines.
- Tesseract then performs Character Recognition, which in the legacy model is somewhat like this:
- The older model recognizes the character patterns, and it separates the image into two blobs. The first blob uses a static classifier and the second one uses an adaptive classifier to improve accuracy.
- The new model uses a neural network LSTM which is faster and quite modern. It recognizes whole lines of text rather than single characters like the older version.
- The last step is called post processing, where the text is formatted and saved. It provides a variety of output options such as plain texts, structured formats such as hOCR that hold positional data and searchable PDFs. For developers, you can access it via a dedicated API or programming wrappers for Python.
Tesseract OCR Installation Screenshots
Walk through each setup step visually with this screenshot slider.

What do users say about Tesseract OCR?
Real feedback from teams, tools, and developers
Community & Contributions
⭐ Star Tesseract OCR
Support the project by starring it on GitHub. Community support helps keep development active and growing.
Star on GitHub🐞 Report Issues
Found a bug, unexpected output, or recognition problem? Help improve accuracy by reporting issues.
Report an Issue🔄 Contribute Code / Fork
Want to improve the engine or add features? Fork the repository and submit development contributions.
Fork the Project⚙️ View Build & CI Workflows
Check automated build pipelines, test systems, and CI/CD workflows powering Tesseract development.
View GitHub ActionsFAQs
Common questions answered clearly
Tesseract OCR is a famous open source Optical Character Recognition software that converts texts in images and PDFs into machine readable texts. It uses pattern recognition and neural network (LSTM) technology to recognize text characters and structures.
Being free and open source, it is considered the best text detection tool that you can actually train. You can customize and train the Tesseract software according to your needs and can use up to 100 languages and 37 scripts.
No, Tesseract OCR is not owned by Google. Google sponsored the development from 2006 till November 2018, but it has always been open source (released under Apache License 2.0). It is now maintained and managed by the community within the Tesseract-OCR GitHub organization. Google no longer maintains it.
Tesseract OCR is considered better because first of all, it’s free. Secondly, Tesseract is faster by 0.7 seconds on average. Google Cloud Vision is paid and cannot be trained or customized. Tesseract also has a better page layout analysis as well.
Tesseract OCR is absolutely free and open sourced. It is released under the Apache 2.0 license, which means you can use, modify, train, and share it freely for both personal and professional use or business projects.
Originally, Tesseract was developed by Hewlett-Packard (HP) between 1984 and 1995 and was open sourced in 2005, but later in 2006, Google sponsored the development till November 2018. Since 2018, it has been community-maintained, with contributors including Stefan Weil and the Mannheim University Library.
Yes, modern versions of Tesseract OCR like 4.0 and later use a system based on Long Short-Term Memory which is LSTM neural networks for text recognition. LSTM is particularly effective at recognizing whole lines of text rather than single characters.
Yes, Tesseract OCR is safe because it is open-source and hosted on GitHub, which maintains code integrity through version control and community review. When you launch Tesseract on your own device, your data stays local and will not be sent to external sources for processing.
Final Words
Tesseract OCR is a tool that you must try if you want an accurate detection of texts in images.
Being a free and open source software, it is quite ahead of its time.
The kind of accuracy it delivers is something to talk about.
The best part is that it’s quite easy to use, but it can be a little complex for beginners.
If you want a free and better than most text detection software, then Tesseract OCR stands as one of the best on the market.
Just a little practice, and you’ll master it.